I recently heard that a major aircraft engine manufacturer blamed an engine control fault on a bit flip, meaning a cosmic ray made it to the Electronic Engine Control and rewrote the software. I'm not sure I buy this.
— James Albright
Updated:
2024-12-15
In the days before cell phone cameras, unexplained phenomena were answered with "CND," could not duplicate. As aircraft have become more and more computerized, some issues defy solution because it seems there is just so much software, nobody has a handle on everything. Could a cosmic ray have caused the problem? Sure, it's possible. But once again, I'm not so sure.

1
What is a bit?
A bit is a solitary item of information that is either true or false. You generate a bit electrically with a switch which is either connected or isn't.

A simple switch in a simple circuit
A transistor is basically a switch. You sandwich one "semiconductor" between two others. Depending on what kind of voltage you give the semiconductor in the middle, the two semiconductors on the outside are connected or aren't.
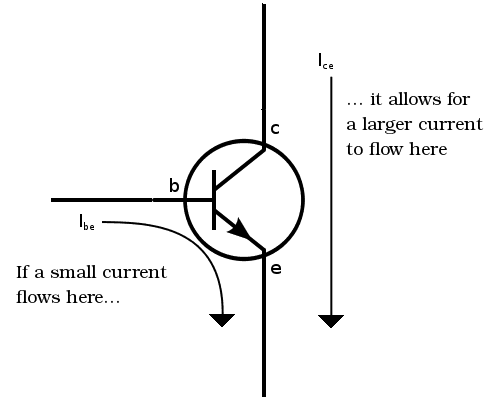
An example transistor diagram
So our simple electronic switch can turn a current on or off, and therefore generate a "1" or a "0" as an output. If you put eight of these transistors together, you can increase the possible outcomes from the simple 0 or 1, to any number from 0 to 255. How is that possible?
One byte, as we have seen, can represent a 0 or a 1.
Two bytes, on the other hand, can represent four numbers:
- First byte 0, second byte 0 . . . Number 0
- First byte 1, second byte 0 . . . Number 1
- First byte 0, second byte 1 . . . Number 2
- First byte 1, second byte 1 . . . Number 3
When you add a third bit, the count goes to 8. A shorthand for this effect is found by raising the number of options (2) by the power of the number of bits. So if you do this eight times to form a byte, the number of options is n = 28 = 256.
More about this: Digital Communications.
2
What is a bit flip?
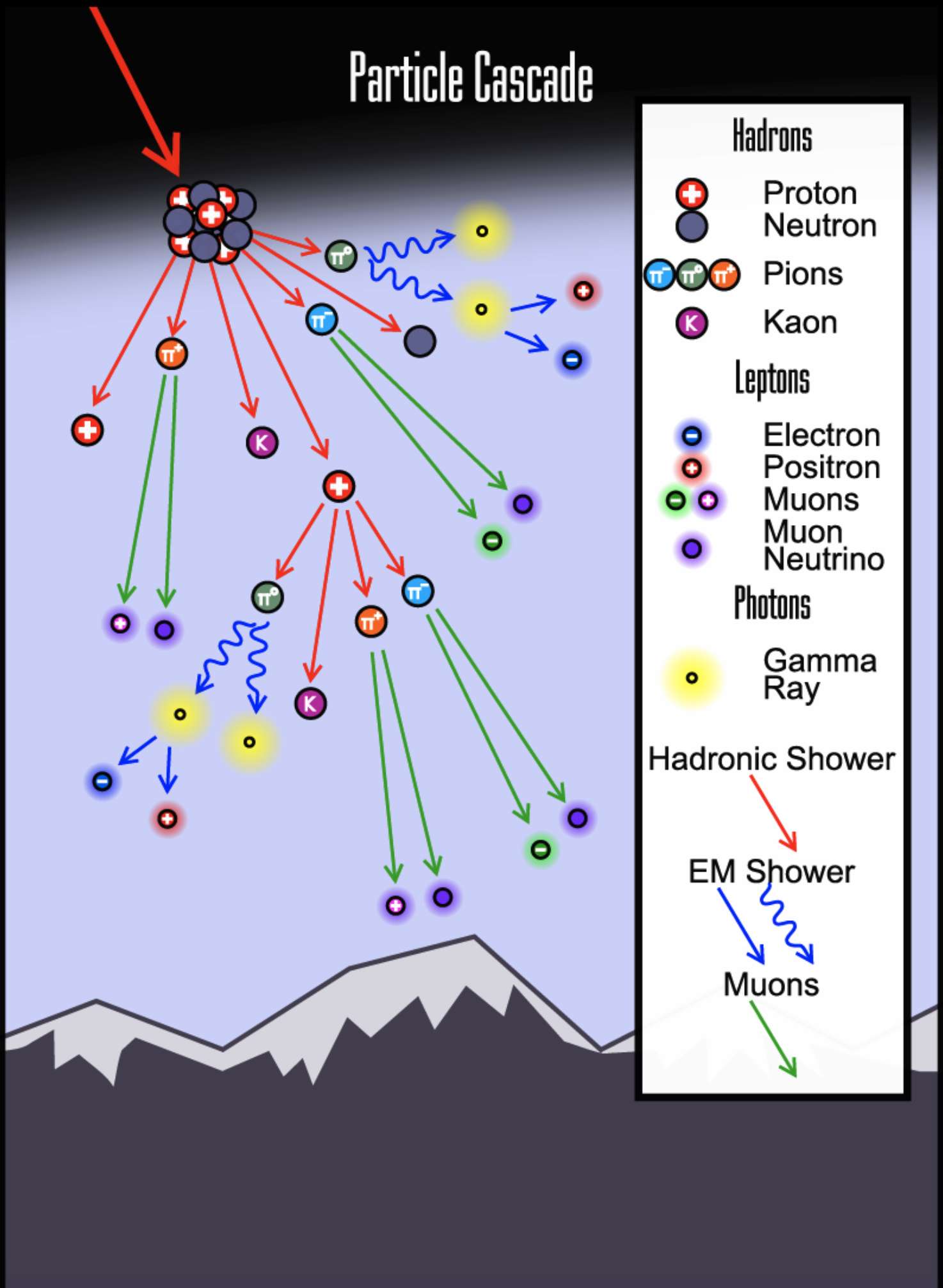
Particle cascade (ScienceABC)
These bits of information are software stored in hardware, something as simple as a magnetic tape but more commonly a switch of sort existing on a sliver of silicon. Imagine, for example, you have a set of instructions for your aircraft dealing with holding an altitude. Those instructions may reside on a sliver of silicon, ready to take action when called upon. Let's say part of that instruction is at set of eight bits that read: 1 0 0 1 1 0. What can go wrong?
In theory, a cosmic ray makes it through the atmosphere, through the skin of your aircraft, through everything leading to that sliver of silicon. It could flip one of those bits to read: 1 0 1 1 1 0. Just one bit has changed, but that could be enough to corrupt that one line of code that allows your autopilot to hold altitude. Of course this is just a hypothetical example. It could be much worse . . .
3
How about an example in aviation?
The classic example of a bit flip in aviation — and perhaps the only recognized example — is the October 7, 2008 case of Qantas Airlines Flight 72, an Airbus A330. The aircraft was flying from Singapore-Changi International Airport (WSSS) to Perth Airport, Western Australia (YPPH), when the aircraft pitched over abruptly several times. For the first event, the aircraft was at 37,000 feet and the autopilot automatically disconnected following warnings from one of the three Air Data Inertial Reference Units (ADIRUs). Two minutes after the disconnect, the aircraft pitched over abruptly to down angle of 8.4°. The captain corrected with aft stick but the fly-by-wire system didn't react for 2 seconds. The problem repeated a few minutes later and the crew correctly decided to land as soon as possible. More about this: Qantas 72.
The issue turned out to be faulty Angle of Attack (AOA) data incorrectly accepted by an ADIRU. AOA probes are known to have "data spike failures" which are filtered out:
- AOA is a critically important flight parameter, and an aircraft with a full-authority flight control system (such as that on the A330 and A340) needs to be designed so that it obtains and uses accurate AOA information. The primary means of defense against an ADIRU providing incorrect AOA data to the FCPCs was the ADIRU itself, but this was not effective on the occurrence flight.
- However, aircraft systems are designed with the expectation that technical faults will occasionally occur. Accordingly, the aircraft had three ADIRUs to provide redundancy and fault tolerance. Using the median of three values for a parameter as the system input is a common and generally robust algorithm, and the A330/A340 EFCS used this approach for most parameters. However, in order to address aerodynamic issues associated with the locations of the three AOA sensors, the FCPCs based the system input on the average value of AOA 1 and AOA 2. Nevertheless, they still used all three AOA values to check for consistency, as a basis for filtering out deviating values of AOA 1 and AOA 2, and for triggering a 1.2-second memorization period using the previous value if an errant value of AOA 1 or AOA 2 was detected.
- The FCPC algorithm was generally very effective, and could deal with almost all possible situations involving incorrect AOA data being provided by one ADIRU. It could manage step-changes, runaways, single spikes, and most situations involving multiple spikes or intermittently incorrect data. For example, the ADIRU data-spike failure mode occurred on 12 September 2006 with spurious stall warnings (and therefore AOA spikes) occurring over a 30-minute period with no reported effect on the aircraft’s flightpath. On the 7 October 2008 flight, there were a large number of AOA spikes transmitted by ADIRU 1, and almost all of these were effectively filtered by the FCPCs.
Source: ATSB Report, ¶5.2.1
The accident report places the term "almost all" as if to say this is okay. If we were talking about a system that simply reported AOA to the pilot I suppose that would be true. But we are talking about a system that has priority over the pilot. If you said a pilot was safe "almost all" of the time, you might think twice before allowing that pilot to fly your passengers.
- Nevertheless, the FCPC’s AOA algorithm could not effectively manage a scenario where there were multiple spikes such that one triggered a memorization period and another was present 1.2 seconds later. The problem was that, if a 1.2-second memorization period was triggered, the FCPCs accepted the next values of AOA 1 and AOA 2 after the end of the memorization period as valid. In other words, the algorithm did not effectively handle the transition from the end of a memorization period back to the normal operating mode when a second data spike was present.
Source: ATSB Report, ¶5.2.1
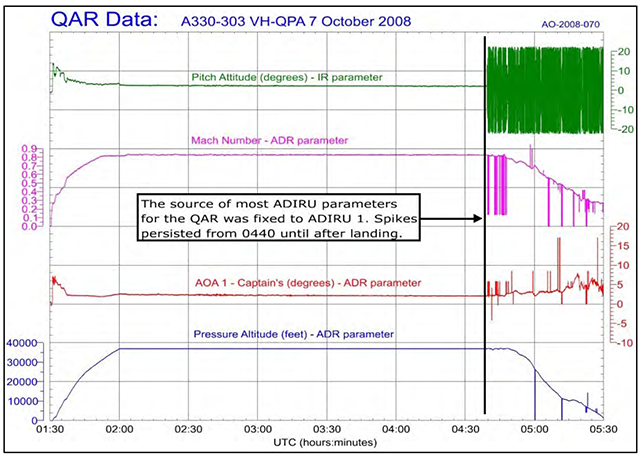
QAR plot showing key ADIRU parameters, ATSB, figure 21.
As best I can decipher this: the ADIRUs average all three AOA values as a way of filtering out deviating values. The ADIRUs also memorize data for 1.2 seconds as a way of having something available to check against the next set of data being wrong (the data spike). But there is a problem. If you get a data spike during one 1.2 second period and another at least 1.2 seconds later, so that it would have occurred after a good 1.2 seconds of data, no worries. But if you get another data spike in the next 1.2 second packet of information, the system is fooled into thinking the data spike is actually good data.
Was this a bit flip?
At the time of the incident, everyone seemed to agree it was the AOA data-spike but since then the bit flip scenario has been suggested. I'm not so sure. Sometimes the obvious answer is correct.
4
How common are bit flips?
A 2024 Example?
A Gulfstream GVII was in cruise flight at 41,000 feet when they received an amber L ENG MAINT Crew Alerting System message for no apparent reason. The Airplane Flight Manual procedure says the cause is "A fault, or combination of faults, has been detected resulting in a DO NOT DISPATCH condition." The corrective action is "Log for maintenance."
I must admit that I have seen this warning many times over the years in this and other Gulfstreams. Maintenance investigates, resets the Electronic Engine Control (EEC), swaps EECs, and finds nothing. When the engine is restarted, the fault clears and we say it is just "one of those things."
What makes this particular instance notable, is the maintenance department chased the problem further and pushed the manufacturer to answer the question, "what happened?" Here is the answer given by Pratt & Whitney Canada:
EEC internal faults can be caused by a Single Event Upset (SEU). An SEU can be best described as a bit flip in a memory element of electronic circuitry caused by high energy particle induction (neutrons). The SEU itself is caused by environmental factors such as cosmic rays that impact the earth’s atmosphere. Upsets are random in nature but more susceptible at higher altitudes. An SEU does not commonly cause any damage. The bit flip error is cleared the next time data is written to the memory location (i.e. EEC Power off Reset)
Really?
I'm not buying it.
In 1992 I had a number of strange display unit problems in a brand new Gulfstream III and the response from maintenance and Gulfstream was, "impossible!" These were in the days before cell phones and we were discouraged from having cameras in the cockpit, so I never had proof. After a while, we started calling these problems with "queer electrons" and these later became "queertrons." Could these have been bit flips? The aircraft were so new, perhaps it was something else . . .
Software problems?
If you've ever flown an airplane that came right from the factory you will probably have experienced what the U.S. Navy calls the shakedown cruise, an initial outing to shake out all the glitches. But in an airplane the shakedown lasts several months. If you are flying a brand-new aircraft type, it could last years.

F-22 Raptor, 17 May 2008, (credit: Rob Shenk)
- Let's consider the F-22 Raptor date line incident. The F-22, at the time, was the pride and joy of the U.S. Air Force. It cost $360 million per aircraft.
- In February of 2007, the first F-22 deployment was made to Japan. They flew a half dozen aircraft across the ocean, across the dateline, to get to Japan. Fortunately they had some tankers with them because when they flew across the dateline, their computers crashed.
- The planes had crashed computers; they had no navigation, they had no communications, they had no fuel management. The only thing that was still working was the fly-by-wire system. So they were able to fly, but they couldn't communicate, they couldn't do anything else.
- They were able to visually follow the tankers back to Hawaii and they got lucky to where they had enough fuel so they were able to land. If they had poor visibility or if something had gone wrong, the pilots would have had to eject and they could have lost all six aircraft.
- The cause was said to be, well, quote, it was a computer glitch in the million lines of code. Somebody made an error in a couple of lines of code and everything goes.
Source: Koopman
- If you're finding it hard to get your head around this, you're not alone. The International Date Line causes all sorts of confusion, and whoever was programming the F-22 must have struggled to work it out. The U.S. Air Force had not confirmed what went wrong (only that it was fixed within forty-eight hours), but it seems that time suddenly jumped by a day and the plane freaked out and decided that shutting everything down was the best course of action.
- Midflight attempts to restart the system proved unsuccessful so, while the planes could still fly, the pilots couldn't navigate. The planes had to limp home by following their nearby refueling aircraft.
Source: Parker, pp. 286 - 285 (the pages are numbered backwards)
It may be tempting to blame problems of bit flips when we can't think of anything else as a cause. But I think more times than not, the software is just more complicated than even the designers realize. More about the F-22 incident: Technophobe.
How common are bit flips in aviation?
I am not convinced any of these examples were caused by bit flips. Qantas 72, the Gulfstream EEC, and even my "impossible" display unit anomalies, are more likely to be software problems. When aircraft software code gets into the millions of lines of code, it is inevitable that one programmer's work conflicts with another's.
5
Bit flips in space?
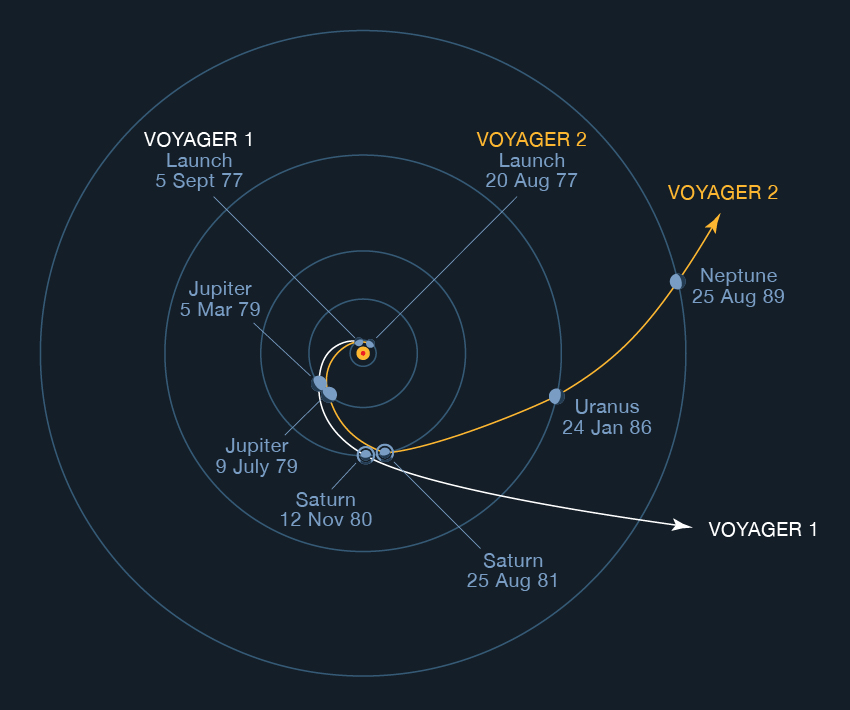
Voyager 1 and 2 trajectories (NASA)
In 2010, Voyager 2 was nearing the edge of the solar system when the spacecraft stopped communicating normally and had to be switched to a backup mode. Because it takes nearly 13 hours for signals to reach the spacecraft and another 13 hours for the reply to reach earth, troubleshooting is understandably difficult. NASA's Jet Propulsion Laboratory finally concluded that, "Yep, it was a flipped bit."
The Voyager 1 team at JPL had traced the problem to the spacecraft’s Flight Data System, an onboard computer that parses and parcels engineering and science measurements for subsequent radio transmittal to Earth. One possibility was that a high-energy cosmic particle had struck Voyager 1 and caused a bit flip within the system’s memory — something that has happened more frequently as the craft navigates the hostile wilds of interstellar space. Normally, the team would simply ask the spacecraft for a memory readout, allowing its members to find and reset the errant bit.
Source: Scientific American
6
What can we do about them?
If your initial reaction is that this is more of design issue than a pilot issue, and that the corrective action is to reboot, then I think you are on the right track . . .
While avoiding cosmic rays can be somewhat impossible for spacecraft once they’ve left Earth’s atmosphere, there are other things we can do to correct a bit flip once it has occurred. Sometimes, rebooting can indirectly clear up the bit-flipped data, resetting it to its original value via memory refresh and reinitialization. However, this technique does not always work, and more robust techniques may be needed.
Sometimes, we use error-correction codes (ECCs) to fix the errors created by bit flips. The codes can detect when a bit flip has taken place, which is usually done by determining the number of 0s or 1s the data contains (provided by the user). If the software detects that there is a mismatch in the number of 0s or 1s from what it received and what the user has provided, it detects the error.
Source: Science ABC
The prime takeaway from all this is we need redundancy in systems. Instead of one fly-by-wire flight control computer, for example, we need at least three so they can take a vote. If you lose all your backups and are down to one system, that system should not be trusted fully. When in doubt, get the airplane on the ground and don't rest easy until everything is shut down and the wheels are chocked.
References
(Source material)
Koopman, Philip, "System level Testing," Carnegie Mellon University lecture 18-642, 9/27/2017.
Parker, Matt, "Humble Pi: When Math Goes Wrong in the Real World," Riverhead Books, 2019, U.K.
"Voyager 1's Immortal Interstellar Requiem," Scientific American, March 14, 2024.
"What are Bit Flips and How are Spacecraft Protected From Them," Science ABC, March 7, 2024.